
Hospitals already have strong processes for evaluating conventional software. Over time, health systems have built rigorous review processes around security, reliability, compliance, and workflow fit. Those processes matter, and they have helped make healthcare’s digital infrastructure safer and more trustworthy.
But those processes were built for systems with fixed logic.
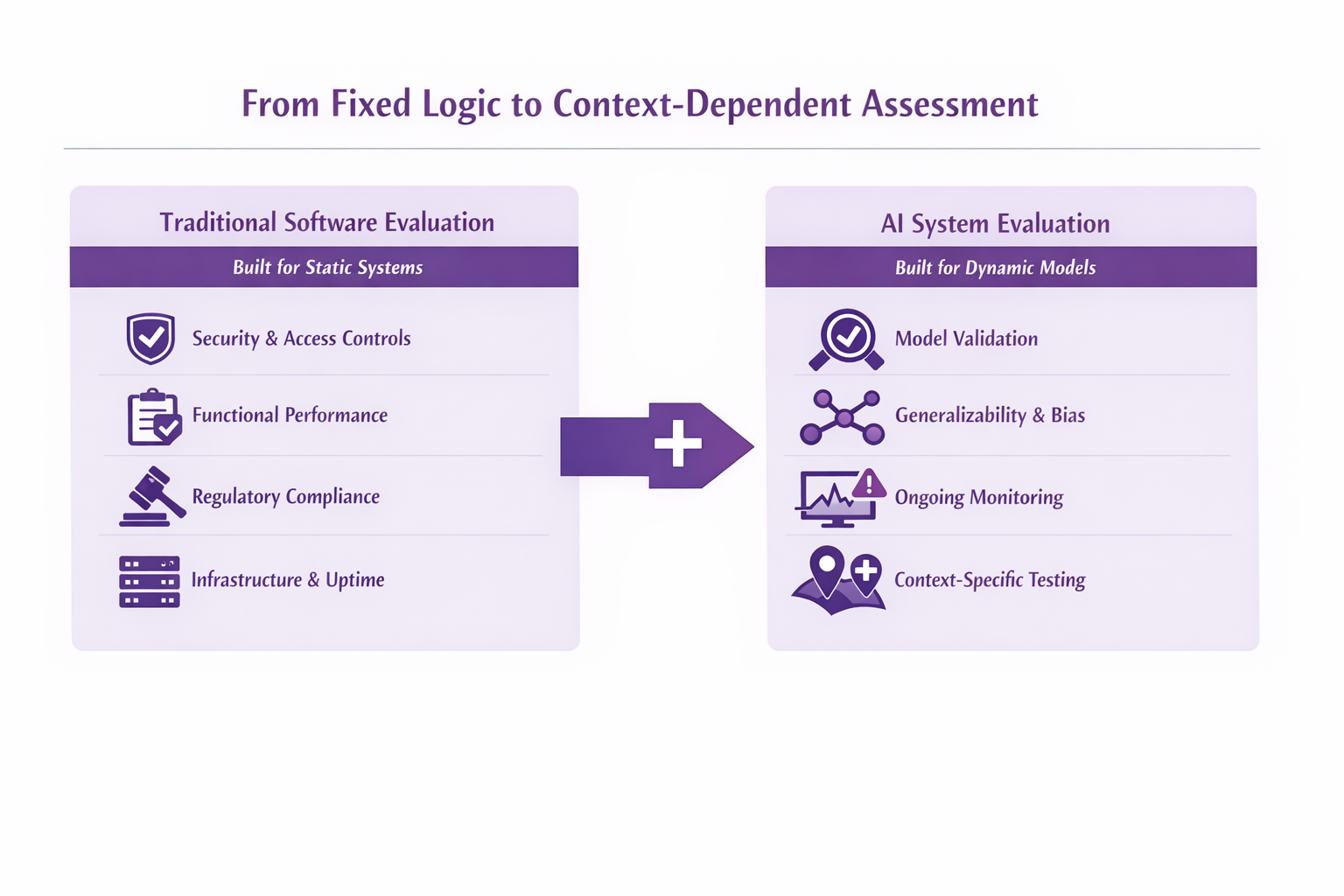
Traditional software is generally deterministic. Once it is validated, its behavior is expected to remain stable unless someone changes the code. AI systems are different. They are probabilistic, nuanced, and context-dependent. Their outputs are shaped by training data, implementation choices, deployment environment, and the populations they encounter in practice. That is where traditional review begins to fall short.
The challenge for healthcare is not that existing software diligence is wrong. It is that it was built to answer a different class of questions.
When hospitals evaluate a new technology vendor, they are not improvising. They already have mature review processes that examine security posture, uptime and resilience, functional performance, regulatory posture, and operational fit. Across security, IT, legal, compliance, and clinical operations, institutions have developed real discipline around how new software enters the environment.
That diligence works well for conventional systems. It helps answer questions like:
Those are important questions. They remain important for AI as well.
Traditional software diligence rests on a reasonable assumption: if the system’s logic is verified, its behavior should remain stable until the software itself changes.
That assumption has held for decades across EHR modules, scheduling systems, documentation tools, and rule-based decision support. If two users enter the same inputs into the same system, the system should return the same result. The logic is explicit. The behavior is predictable. The main risks are implementation defects, configuration issues, downtime, or outdated rules.
Traditional review is built for that world. It is very good at determining whether a system is secure, functional, and ready for deployment.
AI changes the nature of what software is.
Instead of simply executing explicit rules, AI systems infer patterns from data and use those patterns to generate outputs. Even when a model is static at deployment, its behavior is still fundamentally different from traditional software. It is not just following a human-authored decision tree. It is producing outputs based on learned relationships, statistical patterns, and contextual signals that may be difficult to inspect directly.
That matters because AI performance is not just a property of the codebase. It is also a property of the data it was trained on, the population it is used with, the workflow it is embedded into, and the environment in which it is deployed.
A model that performs well in one institution may behave differently in another. A system trained on one documentation style may struggle with another. A workflow that is low risk in one context may become more consequential in another. These are not edge cases. They are natural characteristics of AI systems.
And they are exactly the kinds of issues that traditional software diligence was not designed to fully surface.
None of this makes traditional review obsolete.
AI systems still need security review. They still need vendor diligence. They still need infrastructure checks, access controls, auditability, resilience, legal review, and operational testing. Every AI product in healthcare should still be held to the same baseline standards expected of any other software system.
That foundation remains necessary.
But it is no longer sufficient on its own.
Traditional review can tell you whether a system is built and deployed correctly. It does not, by itself, tell you whether a model will perform reliably across populations, workflows, and real-world conditions.
That is the gap AI introduces.
This is the point where healthcare needs an additional layer of evaluation.
Traditional diligence is designed to assess infrastructure integrity. AI introduces a second question: can the model’s outputs be trusted in the setting where care is actually delivered?
That question is harder because it is not answered solely by checking whether the product is secure, functional, and compliant. It requires understanding how performance changes with context. It requires looking at validation quality, generalizability, subgroup performance, monitoring plans, human oversight, and how directly the system influences clinical action.
In other words, traditional review tells you whether the system works as built. AI-specific evaluation asks whether it will hold up in practice.
Imagine a nurse using an AI-based triage assistant trained on historical call notes from one hospital. At the original site, the model performs well. But after deployment at another institution, patients describe symptoms differently. Older adults say “pressure” instead of “pain.” Local staff document calls in a different style. The underlying population also differs from the one the model was originally trained on.
The interface still works. Access controls are intact. The system is available, integrated, and compliant. The outputs look plausible.
But the model begins under-triaging certain cases.
Traditional review would not necessarily catch that. Security review would pass. QA might pass. Compliance review might pass. The problem is not that the software is broken. The problem is that the model is no longer performing the same way in the new context.
That is a fundamentally different kind of risk.
This is why healthcare needs more than conventional software diligence for AI. It needs an added layer of evaluation focused on real-world model performance.
That includes questions like:
Not every AI tool requires the same depth of review. A documentation aid does not carry the same risk as a model that shapes prioritization, interpretation, or downstream clinical action. But across categories, the principle is the same: AI requires evaluation that goes beyond infrastructure and into performance in context.
This Is Not Just a Better Diligence Problem
I have been deploying artificial intelligence in clinical settings for years, and the problem that stays with me is not the one most people expect. It is not whether the model works. It is what happens after it does.
I know this as a professional. I have led the integration of FDA cleared AI systems into frontline physician workflows across health systems nationwide, and the gap between detection and action is where I have seen the most consequential failures. A flag that goes unseen. A result that sits unrouted. A follow-up that never happens. These are not edge cases. They are the norm in systems that were not built to absorb what AI produces.
I also know this as a patient. It took ten years and a string of dismissed symptoms before I was diagnosed with multiple sclerosis. My records were siloed, no system was looking across the full picture, and no one flagged the pattern. I have also supported my wife through her cancer diagnosis, sitting with her in the same waiting rooms, depending on the same systems to get it right. Behind every scan is a person waiting for an answer that will shape the course of their life. I have been that person. That experience does not leave you when you go back to work.
That is why the procurement question matters more than it is typically framed. This is not just a diligence problem. It is a question of whether the systems we are deploying are built to close the loop, and right now, for most organizations, the honest answer is that they are not.
Most vendors are selling AI systems, not isolated models, and that distinction matters more than it is typically given credit for. In practice, a health system is evaluating a pipeline, not a single component. There may be multiple models, layers of processing, retrieval logic, human review steps and integrations into existing workflows. Each layer introduces potential points of failure, and those failures don't stay contained. A missed prioritization can delay a stroke diagnosis. A poorly surfaced finding can result in a missed follow-up. A breakdown in tracking can leave a known abnormality unaddressed. These are not traditional software defects. They are patient safety risks that emerge from how the system functions as a whole.
Procurement processes often rely on a single validation study, frequently conducted by the vendor on its own data, and treat that as sufficient evidence of clinical readiness. It is not. A validation study reflects performance under specific conditions. It offers limited insight into how the system will behave in a different environment, with a different patient population and embedded in a different workflow. But the deeper problem is not the study design. It is what the study is measuring. Detection is not an outcome. In healthcare, value is only realized when a finding leads to appropriate action and that action is completed. That depends on communication, workflow and follow-up systems that sit outside the model but ultimately determine whether it makes a difference. We obsess over whether the model is right while ignoring whether the system responds at all. Without infrastructure to measure what happens after the flag, procurement is evaluating the reactor while ignoring the grid.
That gap becomes a liability question faster than most organizations expect. When an AI system contributes to a clinical decision that results in harm, responsibility is not clearly defined. It may sit with the vendor, the institution or the clinician, depending on how the system was deployed and used. In practice, most contracts assign a significant portion of that risk to the institution. That arrangement assumes a level of understanding that many organizations do not yet have, not because of inattention, but because the frameworks needed to evaluate these systems are still developing. Liability does not redistribute cleanly when the workflow was never designed to hold it. Organizations that treat this as a legal question rather than a systems design question will find themselves exposed when cases move through regulatory and legal channels.
Organizations that approach evaluation well tend to ask different questions. They look beyond whether a system works and focus on where it may break and what happens when it does. They examine training data, validation populations and whether performance holds across different settings. Just as important, they do not treat evaluation as something that ends at deployment. These systems are affected by changing data, workflows and populations, so performance cannot be assumed to remain stable. It has to be monitored. That means having a clear view of how performance is measured in production, how drift is detected and who is responsible for acting on it. Regulatory approval before a product reaches patients remains necessary. It is simply not sufficient on its own.
That resource asymmetry is the part of this problem that gets the least attention. Academic medical centers generally have the people, expertise and governance infrastructure to monitor AI safety. Smaller community hospitals often do not. The shift toward post-market surveillance only works if the safety nets reach beyond major institutions. A framework built around what large systems can absorb will leave the places with the fewest resources, and often the highest need, exposed. The constraint is not the model. It is whether the surrounding system was built to catch failures when they happen at 2 a.m. in a hospital without a dedicated AI governance committee.
The path forward is not complicated to describe, even if it is hard to execute. Vendors who cannot explain how their system performs after deployment, across different populations and settings, are telling you something important about how seriously they take what happens next. Institutions that route AI through standard software review and call it governance are making a bet that nothing will go wrong in a way that lands on them. That bet is getting harder to win. And without shared infrastructure for measuring performance across health systems of different sizes and resources, accountability remains a concept rather than a practice.
I worked on the Scanxiety Toolkit with the American College of Radiology because patients experience real psychological harm while waiting for imaging results. That harm does not require a missed diagnosis. The wait itself is the burden. When AI generates a finding and nothing moves, that burden extends. Someone is sitting with uncertainty while a flag goes unacted on in a workflow that was never designed to catch it.
The question this piece raises — who is responsible for safety once AI is in clinical use — is not primarily a regulatory question. It is a systems design question. Responsibility does not redistribute cleanly when the workflow was never built to hold it. Organizations that treat liability as a legal problem to be managed after the fact will find themselves exposed. The ones that treat it as a design problem to be solved before deployment will be in a different position entirely.
I have deployed these systems. I have been the patient depending on them. The gap between those two experiences is exactly what better evaluation, stronger governance and shared accountability are meant to close. More intelligence increases the volume of information, the number of decisions and the burden of follow-up. The system has to keep up, and someone still has to own the outcome.
In many industries, software failure is mostly an operational problem. In healthcare, AI failure can carry clinical consequences.
A model that fails to generalize can affect patient prioritization. A model that performs unevenly across populations can create safety and equity concerns. A system whose outputs are poorly understood can erode clinician trust, even when the underlying tool has value. And because healthcare organizations operate in highly regulated, high-stakes environments, the consequences extend beyond workflow disruption into governance, accountability, and institutional credibility.
That is why AI cannot simply be reviewed as just another software vendor category.
Healthcare needs a way to distinguish between software that is secure and functional, and software that is also safe to rely on in context.
Cybersecurity has mature trust frameworks. Hospitals and vendors can use SOC 2, HITRUST, and related controls as shared reference points. AI does not yet have a fully equivalent standard for performance, robustness, fairness, generalizability, or monitoring discipline.
As a result, hospitals are creating their own review processes. Vendors are being asked to provide new forms of evidence. Procurement is evolving. Governance committees are emerging. Expectations around disclosure, validation, and post-deployment monitoring are becoming more common, but they are still far from standardized.
That can make the process feel fragmented today. But it also reflects something important: the industry is actively defining what responsible AI diligence looks like.
The organizations that do this well will not be the ones that abandon traditional software review. They will be the ones that recognize its limits and build the next layer on top of it.
Healthcare already knows how to evaluate conventional software. That is not the problem.
The problem is that those processes were built for systems with fixed logic, and AI systems are not fixed in the same way. They are probabilistic, nuanced, and context-dependent. They can succeed in one environment and struggle in another. They can appear operationally sound while still failing in clinically meaningful ways.
That is why traditional review still matters, but no longer stands on its own.
The next stage of healthcare governance is not about replacing software diligence. It is about extending it: from evaluating whether systems are built correctly to evaluating whether they will perform safely and reliably in real-world clinical use.
That is the shift AI requires. And the institutions that understand it earliest will be the ones best positioned to adopt AI with both speed and credibility.



